中文版:使用K3s部署预算友好的ARM-X86混合Kubernetes集群 – Frank’s Weblog

Kubernetes were used for enterprise level services, which is heavy and expensive. Even for the least-expensive Digital Ocean, its managed Kubernetes starts with $12/month per node. Then I learned about K3s, a lightweight Kubernetes distribution that removes or lightens many of the components in Kubernetes, allowing K3s to run on smaller VMs and even Raspberry Pi while still having the Kubernetes’ features and scalability.
This article will demonstrate at how to build a budget friendly Kubernetes cluster using K3s on Oracle Cloud Free Tier and find a balance between fancy technology and cost. The goal is to migrate some of my personal services that I previously ran using Docker, including Matomo, MariaDB, Mastodon, and several personal services to Kubernetes. This article will focus on the high-level design and concepts, and will not cover specific implementation details.
Deploy K3s
Each free Oracle Cloud user can create up to 2 AMD VMs with 1C1G and 1-4 ARM VMs with up to 4vCPU and 24G RAM. However, since each user can create 4 Block Volumes max, 4 VMs can be created at most. You can arrange the above computing resources to meet your needs.
Oracle’s free AMD VM has very poor performance, I prefer to use the ARM VM to run heavier workloads. But I still keep an AMD VM to run some applications that don’t support ARM for now.
I created 3 VMs for this cluster:
- ARM 2C12G: Control plane and ARM workloads
- ARM 1C6G: ARM workloads
- AMD 1C1G: X86 workloads
Some iptables rules are automatically enabled in Oracle’s VM, we need to remove these rules for K3s to work. To learn how to remove these rules, see: 甲骨文Oracle Cloud免费VPS Ubuntu 18.04/20.04 系统防火墙(UFW和iptables)的正确配置方法 | Coldawn 。
To ensure security, make sure to configure security group from Oracle Cloud Console after removing iptables rules. It’s a good practice to configure all the nodes to use the same security group, and allow all traffic within the same security group, to ensure the communication inside the cluster. The K3s control plane uses TCP 6443 by default, if you wish to operate the cluster over the internet, you’ll need to allow TCP 6443 on both VPC and VM security group.
Networking
Traefik is shipped along with K3s as the default Ingress controller. You can choose to remove Traefik and configure other ingress, such as nginx ingress.
At this time I didn’t use ingress, instead all the services are served via Cloudflare Tunnel. To learn how to deploy Cloudflare Tunnel, see: Deploy Cloudflare Tunnel on Kubernetes – Frank’s Weblog
Deploy workload in ARM/AMD hybrid architecture
As mentioned previously, this K3s cluster is a arm64/amd64 hybrid cluster. Although Docker has supported ARM images for a long time, there are a lot of images that don’t support multi-arch. In order to ensure that containers can run smoothly on all nodes and migrate seamlessly, we need to ensure that the deployed Docker images support Multi-arch.
Most images (operating systems, common software, etc.) now support Multi-arch, such as mariadb, which supports four processor architectures.
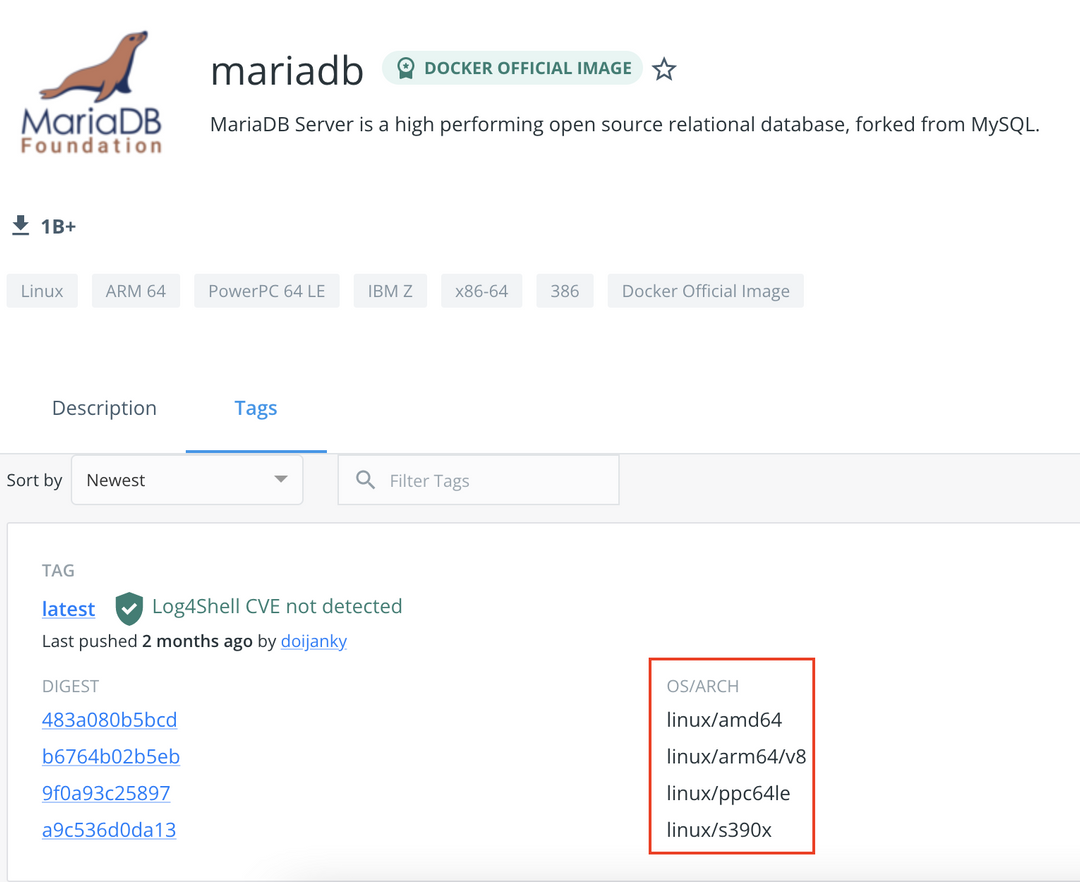
In the case that the application supports Multi-arch images, Pod runs on either arm64 or amd64 VMs. But there is still a lot of software that only supports amd64, such as cloudflared.
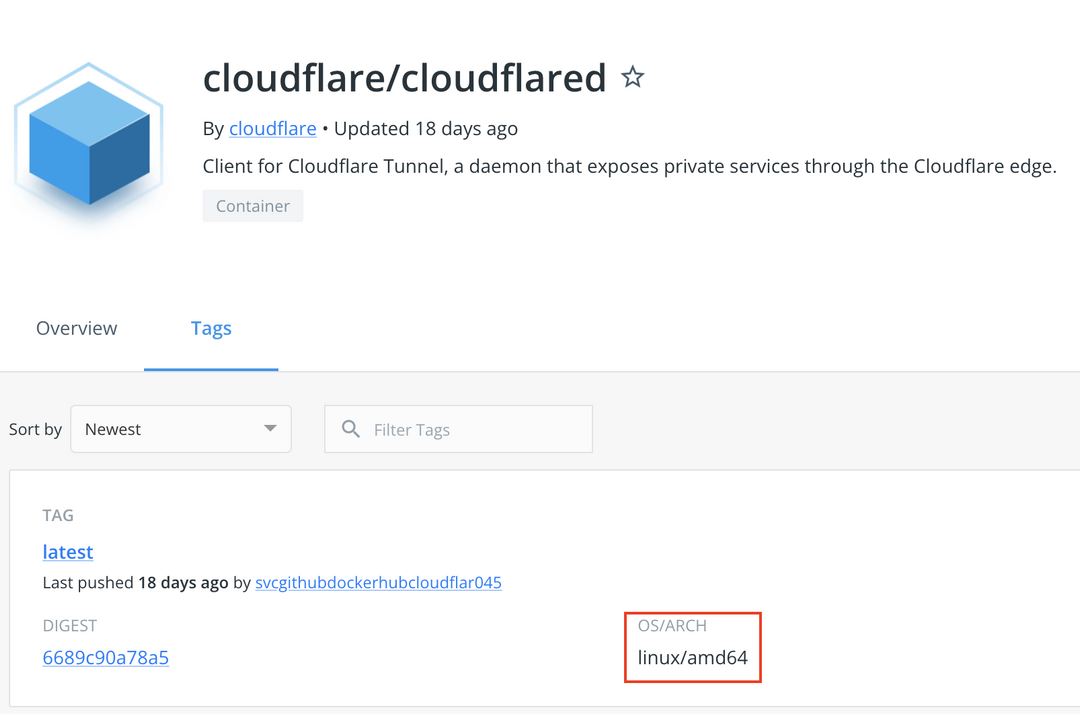
In the case where no multi-arch image is available, we need to use nodeSelector to assign the Pod to an AMD node. If an image only supports amd64 and there’s no nodeSelector or taint in the yaml to configure node assignment, it is possible that the Pod is assigned to an ARM node and failed to start.
If you want Pods to be scheduled to any node, the image must be Multi-arch, otherwise an amd64 only containers might be scheduled to ARM nodes and results in failure. If there is no Multi-arch image available for a particular software, you can build it yourself using Docker Buildx: Buildx | Docker Documentation
Since Oracle’s AMD VM has unsatisfied performance, I want the heavier applications to run on ARM nodes. So I used preferredDuringSchedulingIgnoredDuringExecution rule in nodeAffinity to get these Pods preferred but not forced to be assigned to ARM nodes.
Problems
Some applications provide image that are not Multi-arch, but instead use tags to differentiate the processor architecture of the image. For example, Gitlab Runner’s build tasks on Kubernetes Executor use the gitlab-helper image to provide util functionalities such as git pull. Because the image is not Multi-arch, but uses tag to differentiate architectures, it won’t work for a hybrid cluster.
Storage
Usually enterprise Kubernetes uses CSI driver to dynamically provision storage devices such as EFS or EBS, but for personal use cases it’s too complicated and expensive.
So the solution I have in mind is to use the file system on the VM as the storage device while supporting replication between nodes to ensure data availability, so that there is no need to manually migrate storage volumes when migrating one Pod to another node, as the storage volumes are available on all nodes. But only having availability is not enough, to ensure data security, data needs to be backed up to a third-party storage service, such as AWS S3 or EFS.
I found two open source projects that meet my needs: OpenEBS and Longhorn.
Longhorn
Longhorn is a CNCF project that provides a cloud-native distributed storage platform for Kubernetes and natively supports backup to cloud storage such as AWS S3 and EFS. With Longhorn, you can:
- Use Longhorn volumes as persistent storage for the distributed stateful applications in your Kubernetes cluster
- Partition your block storage into Longhorn volumes so that you can use Kubernetes volumes with or without a cloud provider
- Replicate block storage across multiple nodes and data centers to increase availability
- Store backup data in external storage such as NFS or AWS S3
- Create cross-cluster disaster recovery volumes so that data from a primary Kubernetes cluster can be quickly recovered from backup in a second Kubernetes cluster
- Schedule recurring snapshots of a volume, and schedule recurring backups to NFS or S3-compatible secondary storage
- Restore volumes from backup
- Upgrade Longhorn without disrupting persistent volumes
The architecture is as follows:
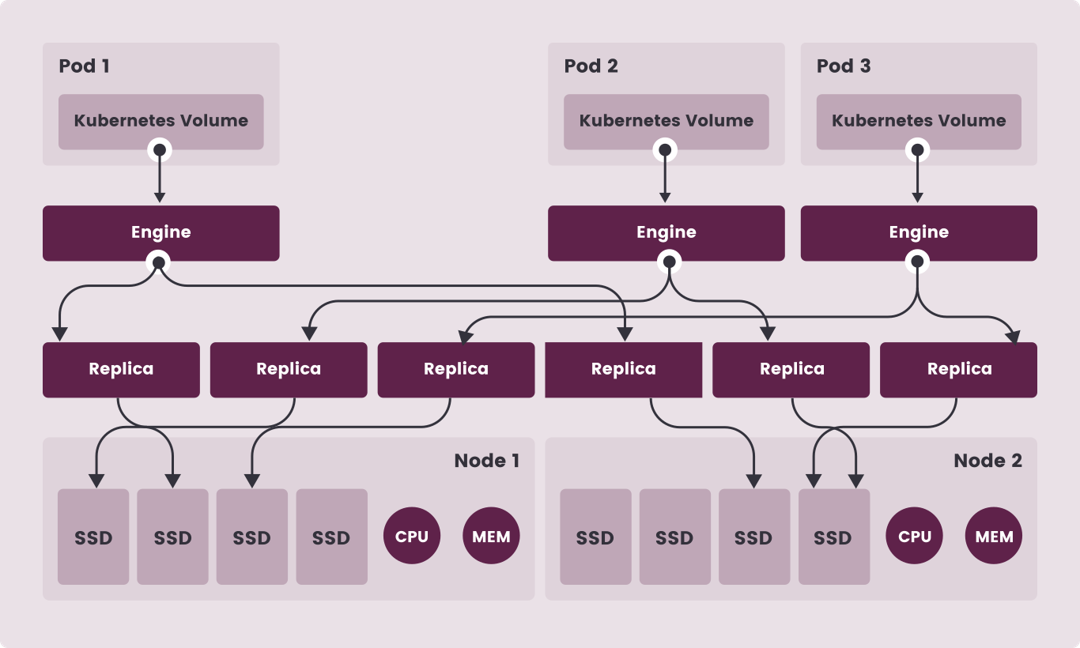
However I found out the minimum hardware requirement is 4C4G x3. After some testing, even if it runs in hardware with lower performance, but it eats up too much CPU and RAM, so I gave up Longhorn.
OpenEBS
OpenEBS is a solution based on the concept of CAS (Container Attached Storage) [2], whose core concept is to use the same microservice architecture for storage and applications, and to achieve resource orchestration through Kubernetes. The architecture is implemented in a way that the Controller of each volume is a separate Pod and is on the same node as the application Pod, and the data of the volume is managed using multiple Pods.
There are three major choices of storage engines for OpenEBS: cStor, Jiva and LocalPV. cStor does not support replication between nodes, and cStor requires a Block Volume as the storage backend, which is not applicable to our scenario.
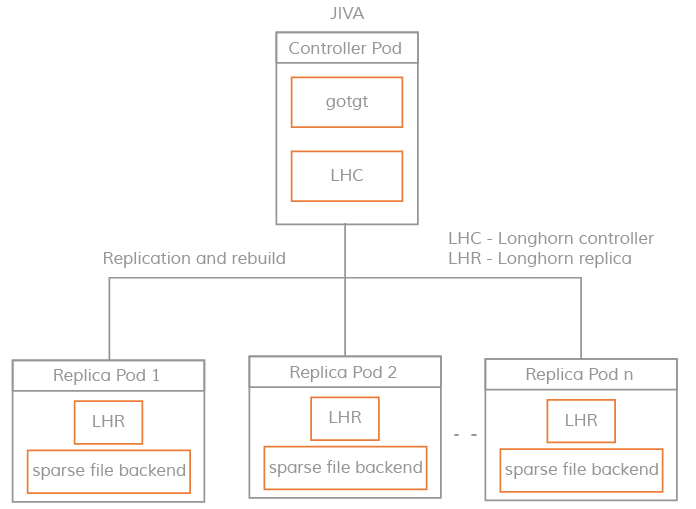
The Jiva storage engine is based on Rancher’s LongHorn and gotgt. Jiva uses sparse files (similar to Sparse bundle on macOS) as the storage backend for dynamic provisioning, snapshots, rebuilds, and other storage functions.
The mechanism of Jiva is very similar to Longhorn, but the hardware requirement is much lower than Longhorn. I ended up with the Jiva storage engine, and since there is replication on each node, the Pod can switch seamlessly between nodes.
Backup
OpenEBS requires the third-party software Velero and its Restic integration to achieve backing up[3][4] to external storage such as AWS.
See: Backup and Restore Kubernetes Volumes with Velero Restic Integration – Frank’s Weblog
References
[1] https://techgenix.com/open-source-storage-projects-kubernetes/
[2] Container Attached Storage (CAS) | OpenEBS Docs
[3] Backup and Restore Stateful Workloads using Velero and Restic | James McLeod

发表回复/Leave a Reply