English version: Deploying Budget Friendly ARM-X86 Hybrid Kubernetes Cluster with K3s – Frank’s Weblog

Kubernetes大多被用于企业级的服务,十分沉重且昂贵。即使是最便宜的DigitalOcean,其Managed Kubernetes最低也需要$12/月每节点。后来我了解到了K3s,一个轻量级的Kubernetes发行版。K3s移除或轻量化了Kubernetes中的很多组件,使得K3s可以运行在较小的VM甚至Raspberry Pi上,同时仍然拥有Kubernetes的可扩展性。
本文将研究如何使用K3s在免费的Oracle Cloud Free Tier上搭建一个预算友好的Kubernetes集群,并在炫酷技术和成本之间找到一个平衡,目标是将我之前使用Docker运行的一些个人服务,包括Matomo,Maraidb,Mastodon以及若干小工具迁移到Kubernetes上来。本文将侧重选型及概念,不会涉及具体实现细节。
部署K3s
每个Oracle Cloud的免费用户可以创建最多2个1C1G的AMD VM,以及1-4个4vCPU和24G RAM的ARM VM。但是受到4个Block Volume的限制,VM最多只能创建4个,但是你可以自行安排上述的计算资源使创建出的VM最大化地符合你的需求。
由于Oracle的AMD VM性能较差,所以我更倾向于使用ARM VM来运行较重的工作负载。但是我仍然保留了一个AMD VM来方便运行一些暂时不支持ARM的应用。
最后我为这个集群创建了三个VM:
- ARM 2C12G:用于control plane和ARM工作负载
- ARM 1C6G: 用于ARM工作负载
- AMD 1C1G: 用于运行一些x86 only的工作负载
Oracle中的VM镜像自带了一些iptables规则,为了方便我们需要把这些规则都移除掉。具体做法请参考:甲骨文Oracle Cloud免费VPS Ubuntu 18.04/20.04 系统防火墙(UFW和iptables)的正确配置方法 | Coldawn 。
为了安全起见,移除iptables规则后请务必从Oracle控制面板为配置安全组。可以将集群的所有节点配置为使用同一个安全组,并将安全组内的通信全部放行,以保证Kubernetes内部的通信。K3s的Control Plane默认使用TCP 6443端口,如果你希望从外部通过公网操作K3s集群,需要在VPC安全组及VM安全组上分别放行TCP 6443端口。
网络
K3S自带Traefik作为默认的Ingress controller。我们可以选择移除Traefik并自己配置其他Ingress,比如nginx ingress。
由于我将要迁移过来的应用大多是个人使用,无需考虑从中国的访问体验。因此我放弃了使用ingress,而将所有服务都通过Cloudflare Tunnel提供访问。部署Cloudflare Tunnel的具体操作请参考:在Kubernetes中部署Cloudflare Tunnel – Frank’s Weblog
在ARM/AMD混合架构中部署工作负载
前文提到我的K3s集群是一个arm64/amd64混合集群。虽然Docker早已支持ARM镜像,但是为了保证容器可以顺利运行在所有节点并无缝迁移,我们需要确保部署的Docker镜像支持Multi-arch。
现在大多数镜像(操作系统,基础软件等)都已经支持Multi-arch,例如图中的mariadb,支持四种处理器架构。
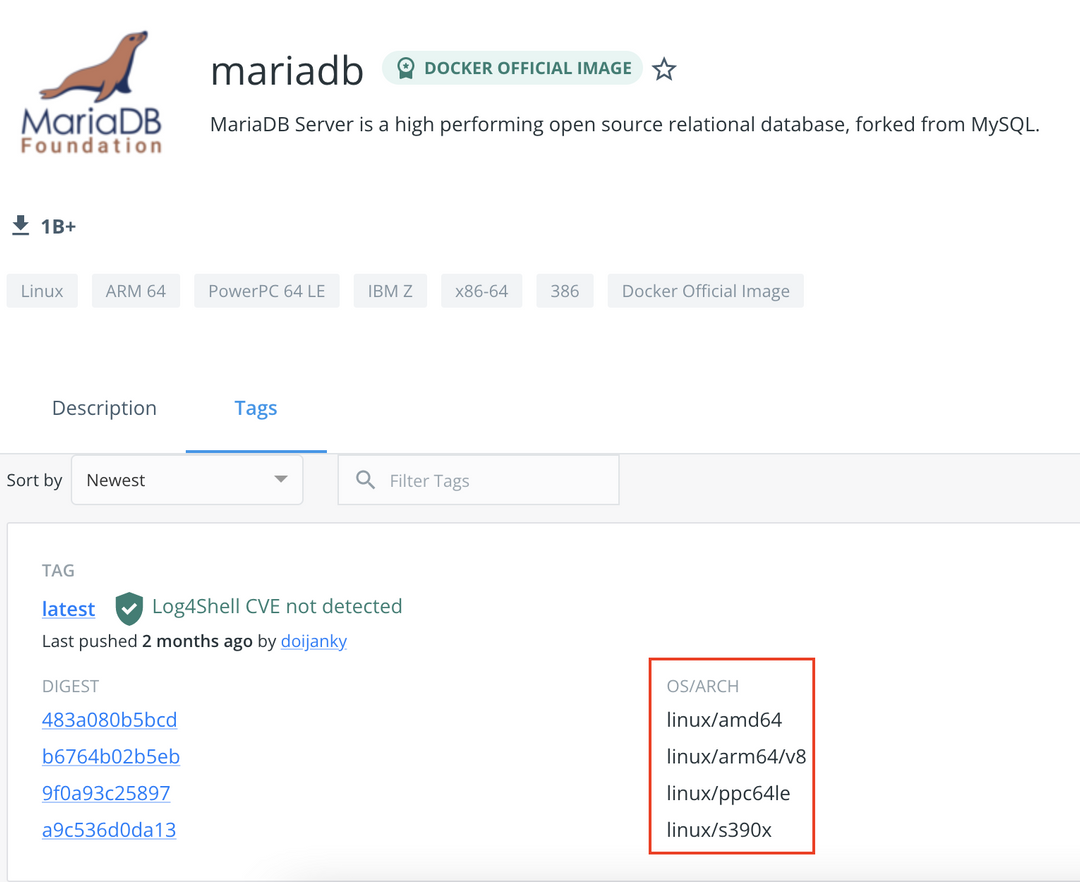
在应用支持Multi-arch镜像的情况下,Pod在arm64或amd64处理器上均可运行。但是仍然有很多软件只支持amd64,比如cloudflared。
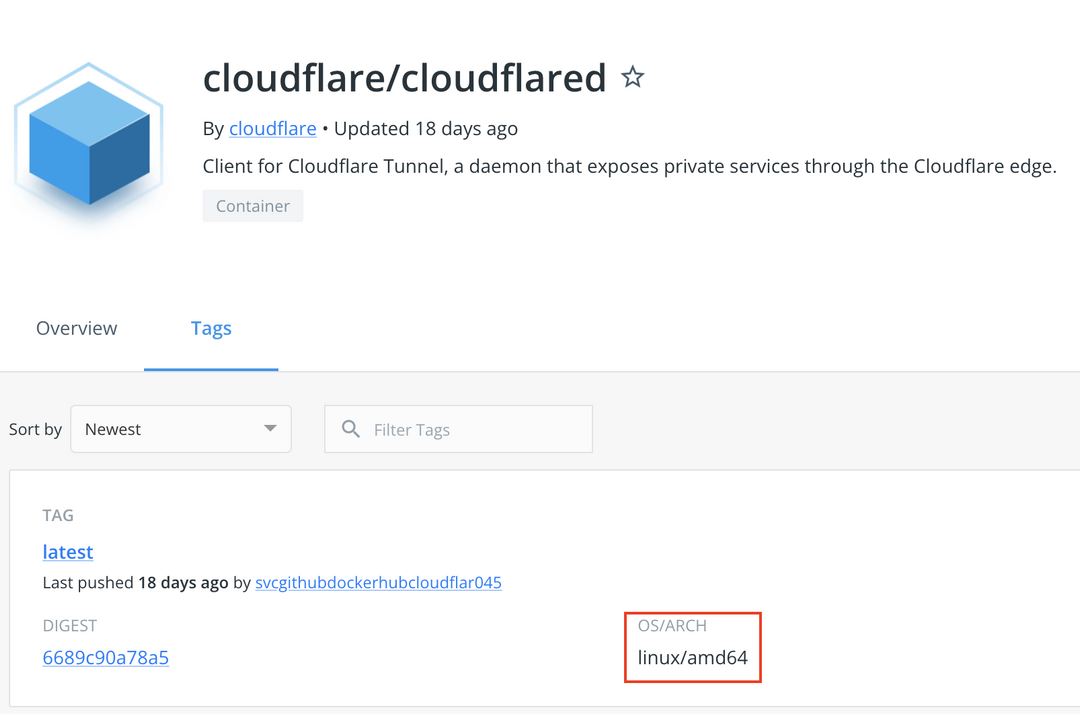
在没有multi-arch镜像可用的情况下,则需要使用nodeSelector来将Pod强行分配到amd节点上。
如果一个镜像仅支持amd64,并且在yaml中没有使用nodeSelector或taint来自定义镜像分配,则会出现Pod被分配到ARM节点并且无法启动的情况。
如果希望Pod可以被Schedule到任意节点上,则必须使用Multi-arch镜像,否则可能会出现仅支持amd64的容器被Schedule到ARM节点导致启动失败的情况。如果没有可用的Multi-arch镜像,可以使用Docker Buildx自行编译:Buildx | Docker Documentation
由于Oracle的AMD VM性能很差,所以我希望比较需要性能的应用都运行在ARM节点上。因此我使用nodeAffinity的preferredDuringSchedulingIgnoredDuringExecution规则让这些Pod优先(但不是强制)被分配到ARM节点。
待解决的问题
一些应用提供的镜像并非Multi-arch,而是通过标签来区分镜像的处理器架构。例如Gitlab Runner的在Kubernetes Executer上执行构建任务时会使用gitlab-helper镜像来提供git pull等功能。但是由于该镜像并不是Multi-arch,因此当Pod被Schedule到ARM节点时则会出现问题。
存储
通常情况下企业级的K8s存储会使用CSI driver来动态provision EFS或者EBS等存储设备,但是对于个人使用来说这种方式过于复杂和昂贵。
因此我设想中的方案是,直接使用VM上的文件系统作为存储设备,并且支持节点之间的replication从而保证数据的可用性,这样在将一个Pod迁移到另一个节点时无需手动迁移存储卷,因为存储卷在所有节点上都是可用的。但是仅仅有可用性还不够,要确保数据的安全性,需要将数据备份到第三方的存储服务,如AWS S3或EFS。
针对这种需求,我找到了两个开源项目:OpenEBS和Longhorn。
Longhorn
Longhorn是一个CNCF项目,为 Kubernetes 提供的云原生分布式储存平台,并且原生支持备份到AWS S3 EFS等云存储。其主要特性有:
- 将Longhorn卷用于有状态应用程序的持久性存储。
- 将您的块存储划分为Longhorn卷,以便您可以在有或没有云提供商的情况下使用Kubernetes卷
- 在多个节点和数据中心复制块存储以提高可用性
- 在NFS,AWS S3等外部存储中备份或恢复数据
- 创建跨集群的灾难恢复卷,以实现快速恢复
- 为卷生存周期性快照,并备份到NFS或S3兼容的外部存储
其架构如下:
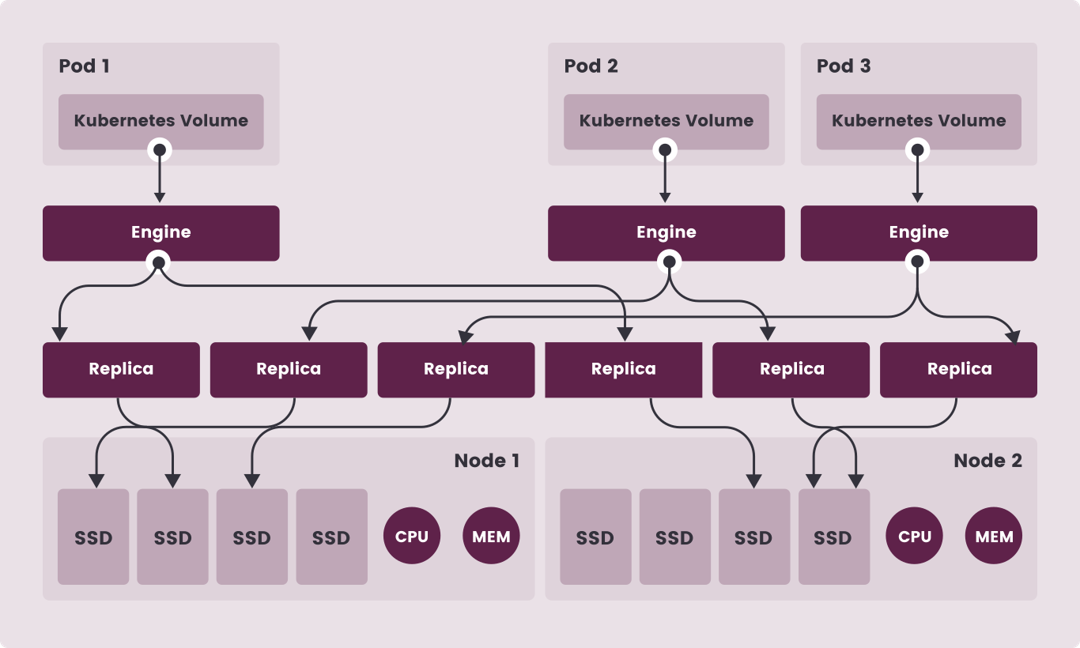
然而经过研究发现Longhorn的最低硬件要求为4C4G x3。经过试验虽然在较低硬件配置的VM中也可以成功运行,但是占用了过多的CPU和内存资源,于是放弃。
OpenEBS
OpenEBS 是一种基于 CAS(Container Attached Storage) [2]理念的容器解决方案,其核心理念是存储和应用一样采用微服务架构,并通过 Kubernetes 来做资源编排。其架构实现上,每个卷的 Controller 都是一个单独的 Pod,且与应用 Pod 在同一个节点,卷的数据使用多个 Pod 进行管理。
OpenEBS的主要的存储引擎有三种:cStor, Jiva和LocalPV。其中Local PV不支持节点之间的replication,而cStor需要使用Block Volume作为存储后端,不适用于本文的场景。
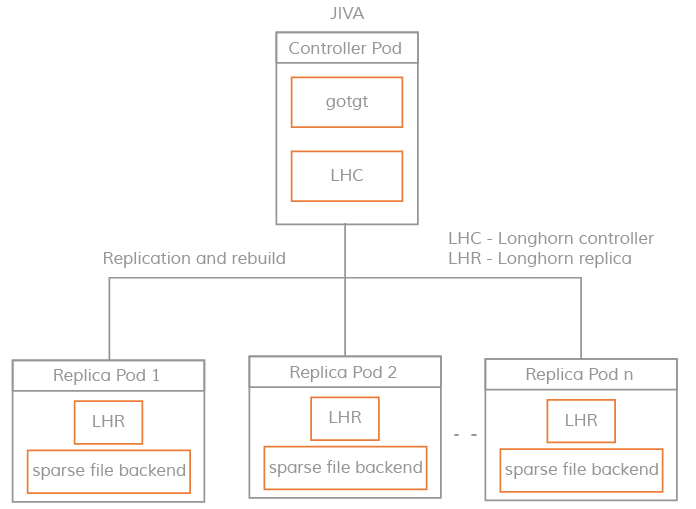
Jiva 存储引擎基于 Rancher 的 LongHorn 和 gotgt 开发。LongHorn 控制器将传入的 IO 同步复制到 LongHorn 复制器上。Jiva使用稀疏文件(类似Sparse bundle)为存储后端,进行动态供应、快照、重建等存储功能。
Jiva的原理和Longhorn非常相似,但是资源占用则比Longhorn小很多。我最后选用了Jiva存储引擎,由于数据在每个节点上都有一份副本,Pod可以在各个节点之间无缝切换。
备份
OpenEBS需要借助第三方软件Velero及其Restic集成实现备份[3][4]到AWS等外部存储。具体操作请参考:使用Velero Restic集成备份及恢复Kubernetes数据卷 – Frank’s Weblog
References
[1] https://techgenix.com/open-source-storage-projects-kubernetes/
[2] Container Attached Storage (CAS) | OpenEBS Docs
[3] Backup and Restore Stateful Workloads using Velero and Restic | James McLeod

发表回复/Leave a Reply