Contents
Problem
This site is hosted in a single AWS Lightsail instance in Japan West region, it has perfect performance when visiting from near by regions, however it has poor performance if visiting from another continent.
- Poor TTFB and LCP from US East and Europe
- Core Web Vital fails because of slow LCP, which impacts SEO performance.
I’ve been using WordPress to run this site for almost 10 years. WordPress have been a very successful software in blogging, CMS and even e-commerce. Comparing with static solutions, it takes more effort to optimize its performance, because of its “dynamic” nature.
I’ve done a lot of performance tuning for this site, and it already archived ~150 ms TTFB from nearby cities, it’s not possible to optimize any further from the server side. It’s also very difficult to optimize the time that data travels between visitors and the server, since the speed of the packet is limited by the speed of light, and we don’t have the control to the routing of the packets.
Idea
One solution that came up to my mind is to add more origin servers and make them distributed all over the world. The visitors will hit the nearest server to eliminate the latency, it also makes the site HA by rerouting the visitors to the working site in case one of the servers is down. While there are some managed WordPress hostings that provide this feature, but these services are very expensive.
I decided to conduct a proof of concept for this idea. The goals are:
- <500 ms TTFB globally
- Highly available
- Scalable
- Budget friendly
This article will cover the design and implementation of a geographically distributed WordPress architecture, and review the design based on its performance, cost, maintainability and scalability.
Design
We can break down the problem into following pieces:
- Global load balancing and proximity routing.
- VPN tunnel to interconnect servers.
- MariaDB/MySQL replication.
- Read-write split.
- Synchronize disk cache purging.
Architecture
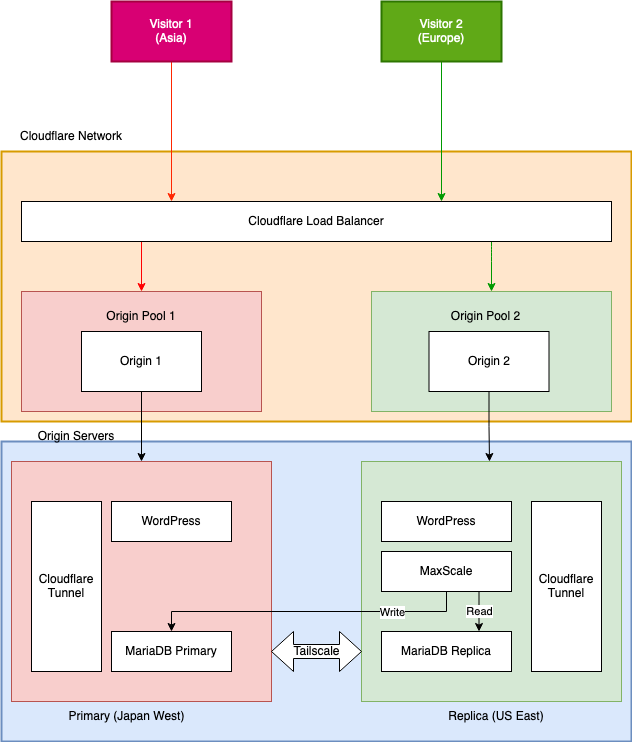
There are two nodes in the system, one in Japan West, the other one in US East. The two nodes are connected to the Tailscale network and can be reached at the Tailscale IP address (100.x.x.x) and Magic DNS name (xxx.tailxxxx.ts.net). You can always add more nodes to the system as replicas. The primary node will be the single source of truth, while replicas can be added and removed as needed.
The two nodes don’t necessarily need be hosted by the same cloud provider, however, placing all nodes in the same cloud provider, and configure them to be connected through the internal network backbone will help decrease the latency.
Cloudflare Load Balancer
Cloudflare load balancer will be the entry point of the visitors.
Unlike traditional load balancers, which only resides in one region, Cloudflare load balancer is global, and can be configured to route visitor to the geographically nearest origin pool.
I created two pools, for two nodes in Japan and US, and configure the location of the pool. The load balancer is configured to use the “Proximity” steering method to route visitor to the nearest pool.
See source code for terraform code for the Cloudflare Load Balancer deployment: geo-distributed-wordpress/cflb at main · frankgx97/geo-distributed-wordpress
Configure Cloudflare Load Balancer with Cloudflare Tunnel
Configuring Cloudflare Tunnel with Cloudflare Load Balancer is quite complicated, I covered this part in a separate post: Use Cloudflare Load Balancer with Cloudflare Tunnel – Frank’s Weblog
SSL Termination at Cloudflare Tunnel
SSL encryption and decryption takes time and computing resource. Since the tunnel traffic is already encrypted, you can choose to terminate SSL at Cloudflare Tunnel.
Whether to off load SSL is beyond the scope of this post. There have been plenty of discussion about this topic:
tls – Should SSL be terminated at a load balancer? – Information Security Stack Exchange
In this case, you will need to configure nginx to listen http at port 80, while WordPress site URL still need to be configured to https://example.com. Since WordPress redirects the page if the actually URL doesn’t match the configured URL, it will cause a infinite redirection.
To resolve this problem, add the following code to wp-config.php[5].
define('FORCE_SSL_ADMIN', true);
// in some setups HTTP_X_FORWARDED_PROTO might contain
// a comma-separated list e.g. http,https
// so check for https existence
if ( isset( $_SERVER['HTTP_X_FORWARDED_PROTO'] ) && strpos( $_SERVER['HTTP_X_FORWARDED_PROTO'], 'https') !== false ) {
$_SERVER['HTTPS'] = 'on';
}Database Replication
I choose to use Primary-Replica setup for MariaDB, MySQL also provides similar functionalities. You can also choose other solutions like TiDB and Vitess.
See MariaDB website for detailed steps for setting up a primary-replica MariaDB deployment: MariaDB replication using containers – MariaDB.org
See source code for my MariaDB configuration.
Primary: geo-distributed-wordpress/maria-primary at main · frankgx97/geo-distributed-wordpress
Replica: geo-distributed-wordpress/maria-replica at main · frankgx97/geo-distributed-wordpress
Alternative: AWS Aurora
To eliminate the overhead of managing the database by ourselves, an alternative approach is to use AWS Aurora, a database-as-a-service that offers multi-region replication for disaster recovery and global distribution of data. I didn’t go too deep in this approach because it’s beyond the scope of the topic.
Read-write Split
With the database setup introduced above, the primary database node will be used for reading and writing, while the replicas will be read only.
This will require us to configure the replicas to read from the database replica in the same node or the region, while still write to the primary database node.
MariaDB MaxScale
MaxScale is a database middleware developed by MariaDB, it provides database read-write split, load balancing and failover. I only added MaxScale on the replica node, read queries will be routed to the replica database, while write queries will be routed to the primary database via Tailscale.
See source code for MaxScale configuration: geo-distributed-wordpress/maxscale at main · frankgx97/geo-distributed-wordpress
HyperDB / LudicrousDB
An alternative is using WordPress plugins like HyperDB or LudicrousDB. HyperDB is a WordPress plugin developed by Automattic. It provides an advanced database class for WordPress that supports read-write splitting, shredding, and failover.
However it has not been updated for years, and it’s only tested up to WordPress 6.0.3. LudicrousDB is a fork of HyperDB maintained by community. I tested LudicrousDB master as of Feb 2023 with WordPress 6.1.3, and it worked fine. However it’s not guaranteed to work with future WordPress versions. Use it at your own risk.
Purge Disk Cache(W3 Total Cache)
I used W3 Total Cache for disk cache in WordPress. The pages with disk cache will be served directly by nginx without being forwarded to php. When there’s changes on any pages, W3 Total Cache will purge the cache, but only on the node which processed the request, the cache on the other node will not be purged and will keep serving outdated content.
Sharing the cache directory is the method recommended by W3 Total Cache team[4]. However it won’t work for a cross region setup because of the latency.
I’ve researched two methods
1. Sync cache directory with lsyncd
lsyncd is a tool that watches a local directory trees event monitor interface (inotify or fsevents), then aggregates and combines events and synchronize the changes with rsync. I configured lsyncd to sync the W3 Total Cache page cache directory (default is /wp-content/cache/).
This method works, but it has two major problems. 1) lsyncd has 10-20 seconds latency. 2) lsyncd only syncs one-way, but the latest cache content may be on both nodes.
2. Build a WordPress plugin and an API for purging the disk cache.
I added a API endpoint in WordPress, it will call the W3 Total Cache API to purge the cache when it’s invoked.
I also built a WordPress plugin and hooked the trigger to the save_post and comment_post event on both nodes, it invokes the purge the API on the other node to to purge the cache by post id. It’s also recommended to configure W3 Total Cache to automatically prime the page cache.
See source code:
API: geo-distributed-wordpress/purge.php at main · frankgx97/geo-distributed-wordpress
Review
Performance: ★★★★☆
I ran several tests using Performance Test Tools by KeyCDN and GTmetrics. The TTFB of the new architecture is 2.56x faster globally, and 3.19x faster from US and Europe.
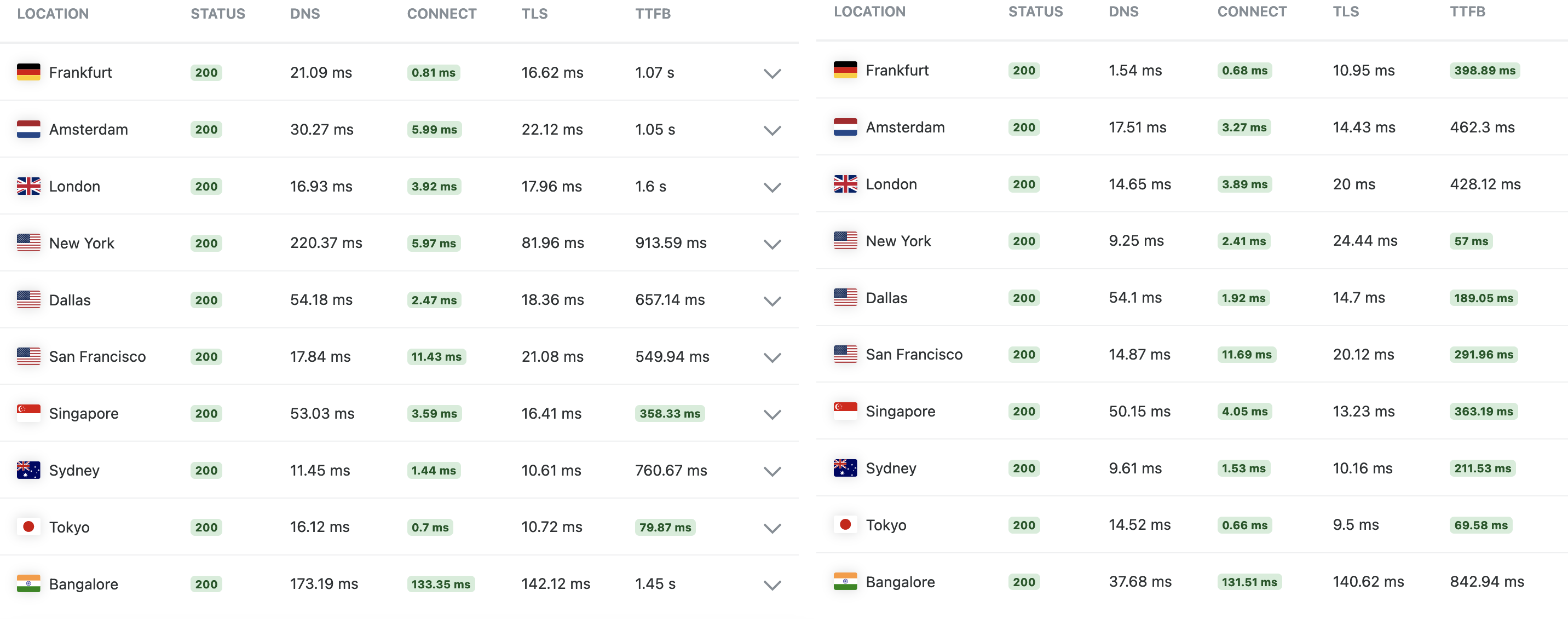
Cost: ★★★★☆
The basic monthly cost of Cloudflare Load Balancer is $5, which includes 2 origin servers. If using $5 AWS Lightsail instance for each origin server. The monthly cost is $15 for a minimal 2 server setup. If you add more servers, Cloudflare Load Balancer will charge $5 for each additional origin server.
It’s a very competitive cost comparing with similar solutions. Azure Front Door charges $35/mo only for base fee.
Maintainability: ★☆☆☆☆
The following pieces need to be monitored or managed:
- WordPress code
- Database replication
- MaxScale
- TailScale
- Health check/probe for WordPress
It creates more work for regular maintenance, eg. upgrading plugins or WordPress version. Currently I do most of the work by hand, but I’ll probably need to build automated pipelines and script to maintain more than one servers.
Multiple origins ideally improves availability, however this requires more complicated observability. Otherwise it’s possible that one origin fails because of unable to connect to DB, while load balancer not able to detect it and still routes traffic to the failed origin.
Scalability: ★★★★☆
All nodes can be scaled vertically by upgrading the origin servers. The system can be scaled horizontally by adding more origin servers to the same pool, or adding more pools in different geographic locations.
However, if there are too many nodes in the system, the disk cache will be difficult to manage. In this case, it would be better to add a Redis cluster and configure W3 Total Cache to use Redis as the backend for page cache.
You can always add more fancy staff if you need. For example, you can add AWS RDS Aurora which supports cross region replication, so that you don’t need to manage the database by yourself.
Source Code
frankgx97/geo-distributed-wordpress
Alternatives
This is not the only solution to improve the networking performance of the website. Here are a few alternatives approach that doesn’t need to manage such a complicated setup.
Static-ize the site
There are plugins like Simply Static to make the WordPress site fully static(like a hexo generator), or simply configure CDN to cache dynamic pages.
This will affect the experience for searching and commenting, but there are workarounds to minimize the impact to the user experience. Personally I value the interaction with visitors via comments, I don’t want to degrade the commenting experience, therefore this is not an option for me.
Move Origin Server to US West
This will somehow slow down visitors from Asia, but it will balance the latency for Asia and Europe, and will cure the Core Web Vital problem.
This will also improve the speed for visitors from China. Although Japan and Hong Kong is geographically closer to China, Cloudflare routes most visitors from China to the Cloudflare data center in the US. Nowadays Cloudflare IP addresses are all anycast, so you can’t directly tell where an IP address locates, but you can still find it out with traceroute.
Argo Smart Routing
Argo smart routing is a technique to optimize the routing between Cloudflare edge and the origin server. It’s a paid add-on that charges $5 per month plus $0.1/GiB. I tried it and turns out it has significant improvement on TTFB.
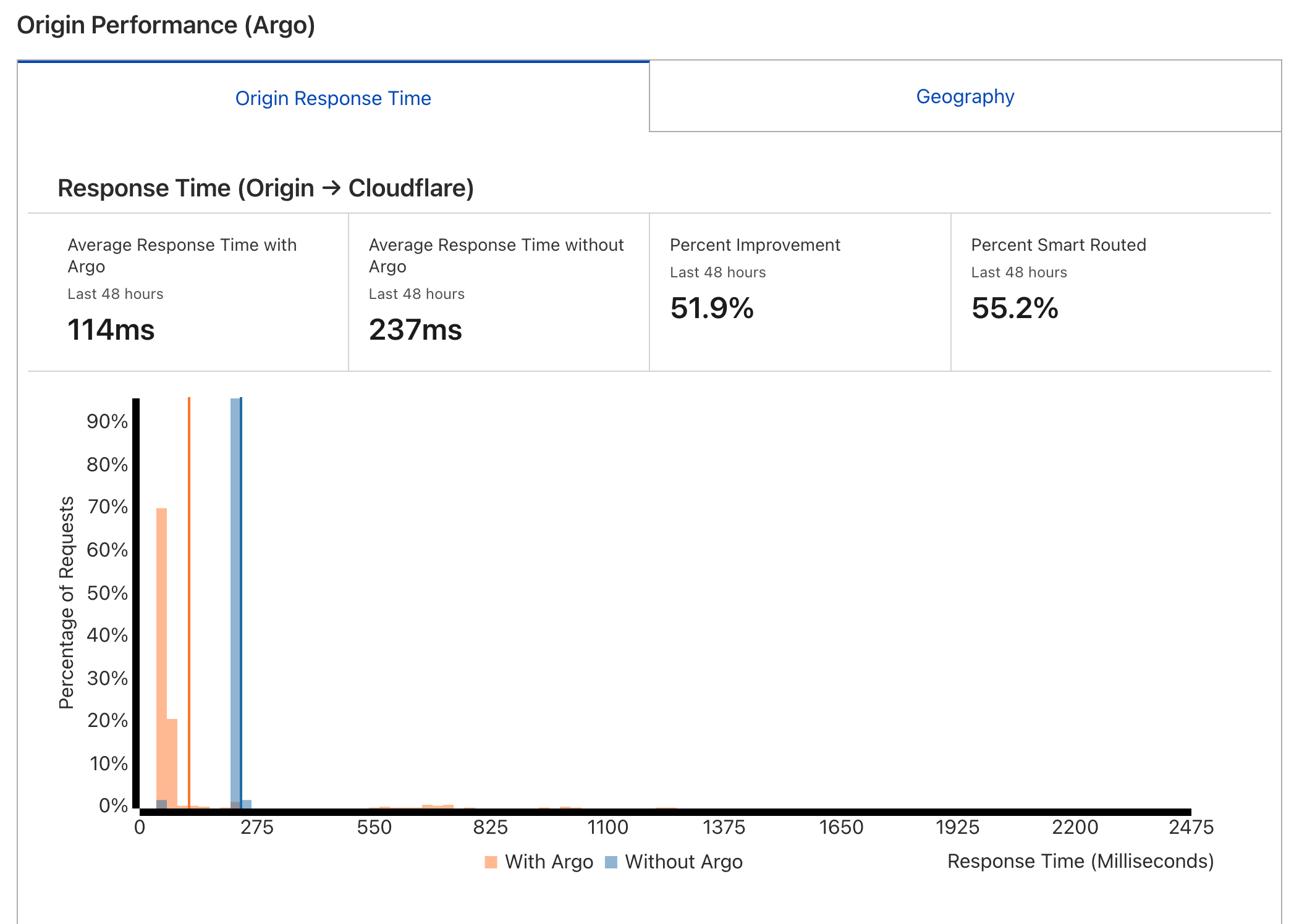
Here is a comprehensive test and review for Argo Smart Routing:
Cloudflare Argo And Railgun Comparison Test, The technology of CDN Acceleration | ZE3kr
Conclusion
The solution achieved significant performance improvement, good scalability and relatively cost efficient. However, it introduced extra complexity to the system which reduces its maintainability therefore may actually lower the uptime.
For my use case, I moved origin to US West region, and enabled Argo Smart Routing. It already does very good job. Currently 88% of the visitors are from Asia and North America, it’s not worth the effort at this time.
References
[1] 20 WordPress Statistics You Should Know in 2022
[2] Cloudflare Tunnel · Cloudflare Zero Trust docs

发表回复/Leave a Reply