English version: Post Mortem for Blog Outage on 2023/1/21 – Frank’s Weblog
2023年1月21日,我的博客受到攻击宕机了4个小时左右。本文将介绍事件的经过,对根本原因的分析,及改进方案。

当天中午,我起床之后看到了UptimeRobot的报警邮件。有时一些网络或者服务器的短暂故障也会触发报警,但是当时距离收到报警邮件已经过去了近两个小时,所以事情显然没有这么简单。我简单检查后发现访问博客时有时完全无法连接,有时会返回504。
我ssh上去之后重启了一下所有Docker容器,但是故障依旧。top显示全部load average高达6.xx并且大部分的CPU使用来自php-fpm。检查nginx amplify图表之后发现过去几小时内nginx收到了大量的请求。
因为当天下午我计划和女朋友去采购年夜饭的食材,不想在这上面花费太多时间,于是我打开了Cloudflare的反向代理(橙色云图标)和Under attack模式,然后就出门了。
过了一段时间后就收到UptimeRobot的报警解除邮件,访问恢复。
我的博客上有一套监控和安全措施,以及一些自动化脚本来mitigate一些简单问题:
- UptimeRobot用于监控可访问性,如果出现无法连接或异常的HTTP状态(5xx)则会发邮件报警
- nginx amplify用于监控nginx和操作系统的指标,其中一些指标(例如磁盘使用,每秒请求数量)超过阈值之后会发邮件报警。
- 如果每秒请求量超过阈值则会自动开启Cloudflare反向代理并升高安全等级。
- WordPress的安全插件会自动block恶意请求。
受益于这些措施,博客在过去几年一直保持着近乎100%的uptime。作为一个每日访问量两位数的博客,4个小时的downtime并不是一个需要担心的问题,但是职业习惯还是让我想知道背后到底发生了什么,尤其是为什么这一系列措施都未能阻止宕机的发生。
分析
除非特别说明,以下所有时间均为美东标准时间(UTC-5)
我导出了nginx的access log,然后使用goaccess工具做了一个简单的可视化(图中时间为UTC)。
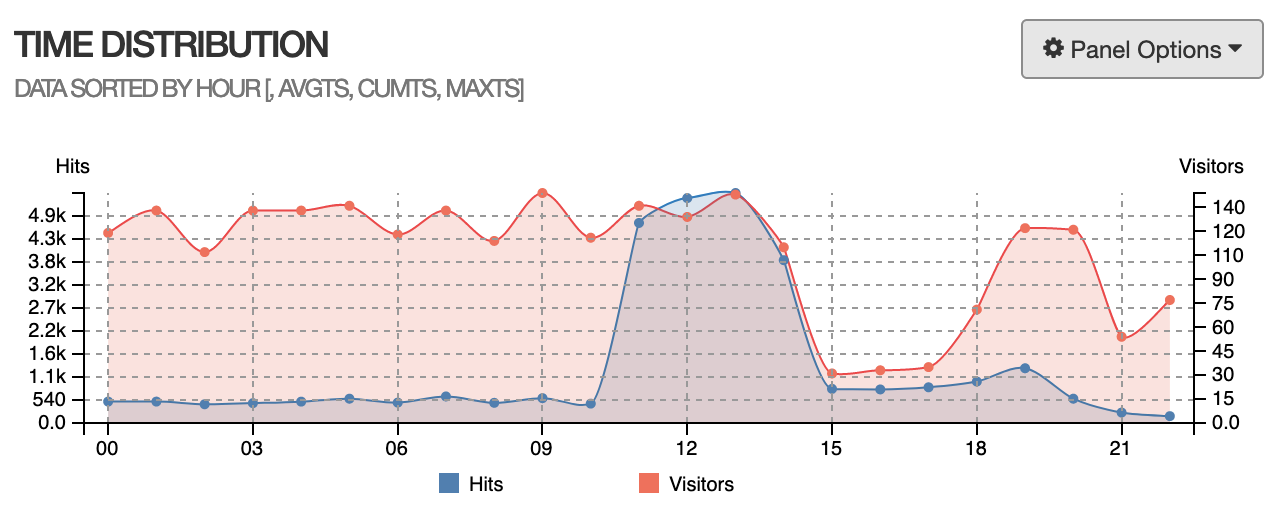
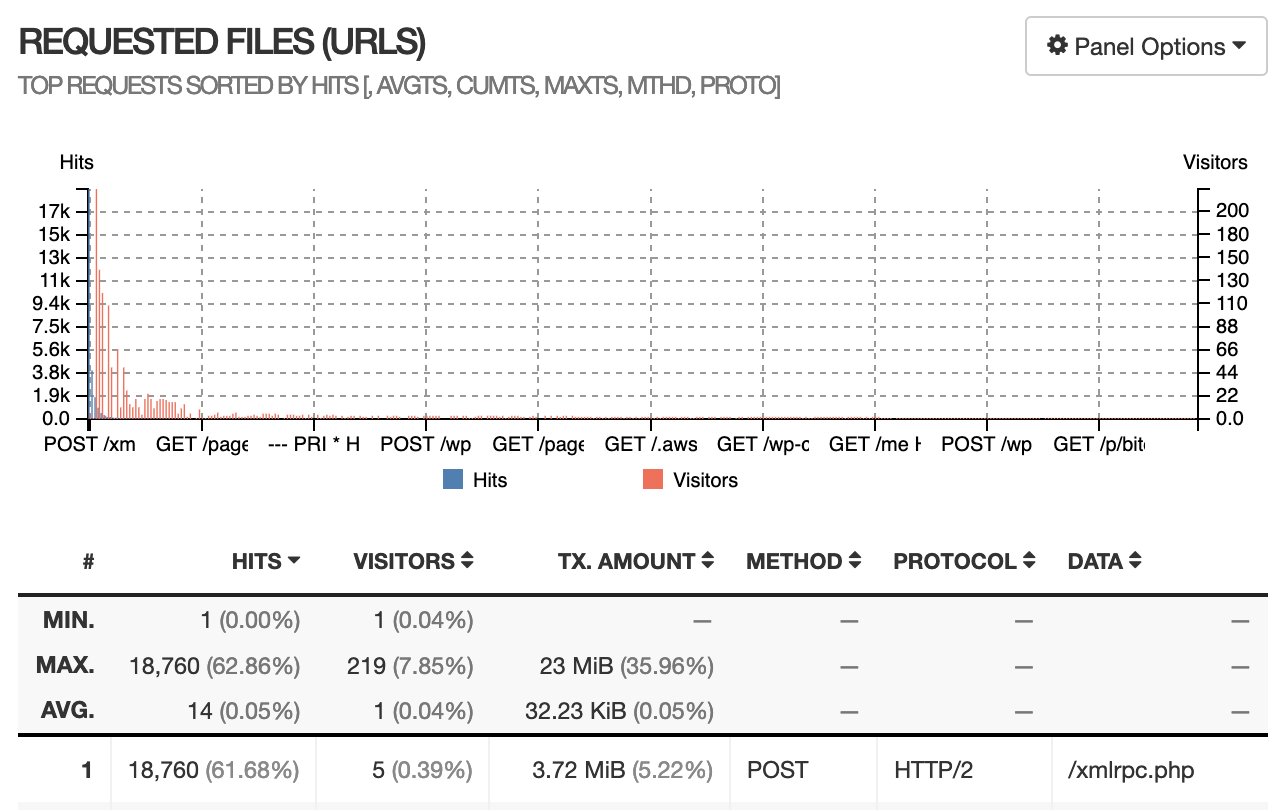
可以看出服务器上收到了大量的POST /xmlrpc.php,body大小均为几百bytes,这是一条记录恶意请求的日志:
172.28.0.1 - - [21/Jan/2023:11:56:36 +0000] "POST /xmlrpc.php HTTP/2.0" 200 212 "https://nyan.im" "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; Trident/6.0)" "-"安全插件通常会自动block掉恶意的请求。然而日志显示这些请求均来自172.28.0.1 ——这是Docker网络的IP,安全插件通常会无视这些内网IP。
我用Python脚本分析了日志,得出攻击的时间分布图表如下(时间为UTC,精确到分钟),可以看出速率大约在80请求/分钟左右。然而自动开启Cloudflare并升高安全等级的脚本需要50请求/秒才会被触发。
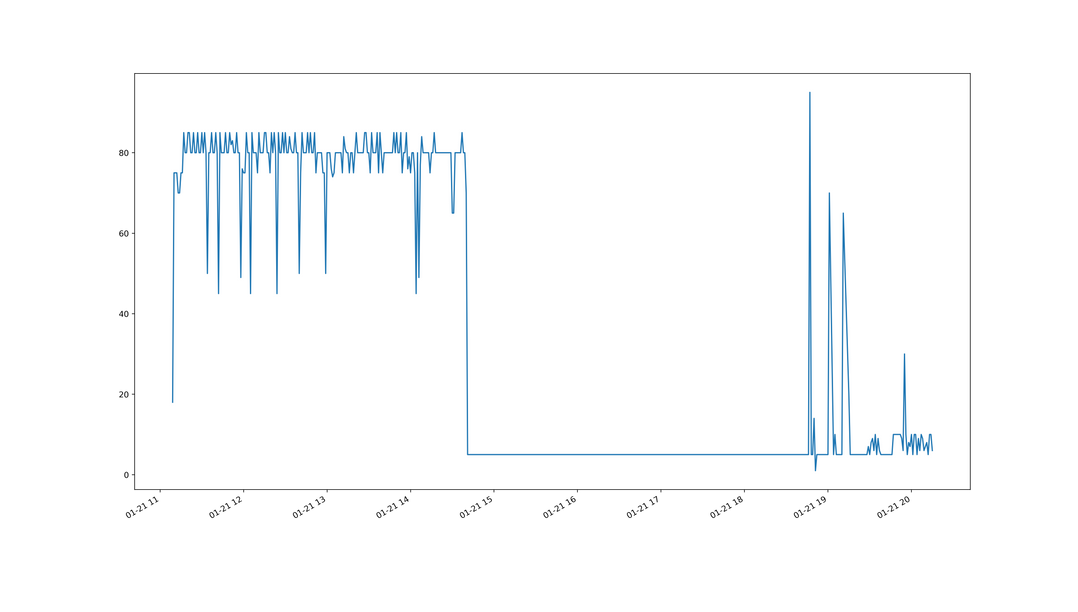
按照上面的图表,每分钟80个平均到每秒也只有不到两个。即使按照nginx amplify显示的每秒并发最高时候8个来算,这点数量并不算高,不至于让整个服务器爆掉。
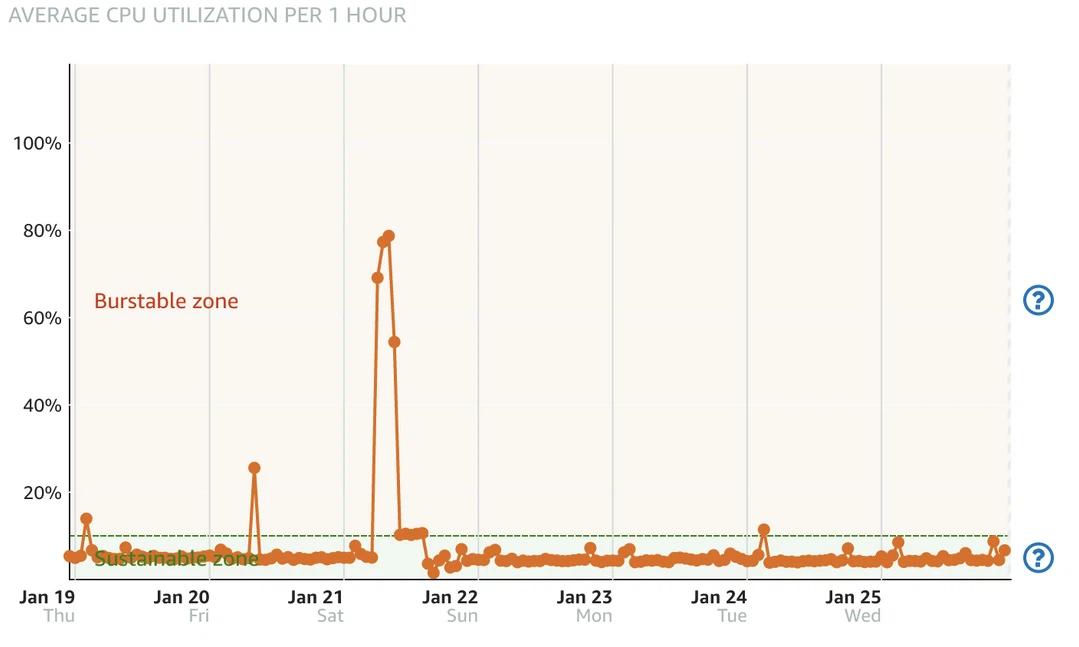
查看Lightsail metrics后发现,Lightsail的计算性能分为Sustainable zone和Burstable zone,由基线(baseline)分隔,各实例类型的基线都不一样,通常来说越大的实例基线越高,对于1C1G的实例,基线是10%。
在CPU使用率高于基线时,就会进入Burstable zone,但同时会消耗Burst capacity,一旦capacity降到0就无法再”burst”,相当于计算性能被限制在了10%。这解释了为什么攻击从6点左右开始,但是直到10点服务器才宕机。
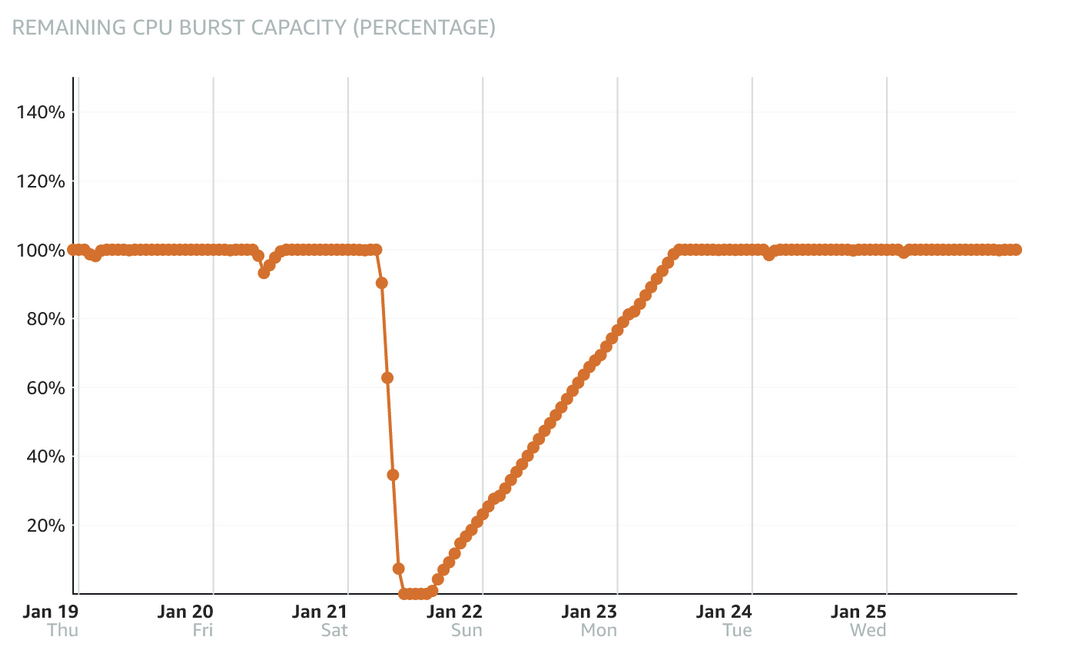
但是还有一个问题我没有搞明白:我使用W3 Total Cache配置了磁盘静态化缓存,正常情况下有缓存的页面会直接由nginx提供服务,无需经过php。nginx处理静态文件的能力很强,即使在计算性能受限的情况下,也不至于完全无法工作。
我检查了W3 Total Cache生成的nginx配置之后,让我大跌眼镜:nginx并没有被配置为直接serve静态缓存,也就是说所有页面还是由php动态生成的。
经过检查发现,我的W3 Total Cache中的Page Cache被配置为Disk Basic,而Disk Basic并不能让nginx直接从返回静态化缓存给客户端而不使用php[1]。正确的配置应该是“Disk Enhanced”。
我回想起几个月之前,我在使用W3 Total Cache配置HTTP/2 PUSH时,因为HTTP/2 PUSH仅支持“Disk Basic”模式,于是我在没有完全理解Disk Basic和Disk Enhanced的区别的情况下将其改为了Disk Basic。
时间线
根据以上分析,我们可以梳理出事件的时间线:
- 6:00 攻击开始,Lightsail Console记录到CPU使用率升高至60%,burst capacity降至90%
- 6:09 密集的攻击开始
- 9:00 – 10:00 之间某个时间:burst capacity降至0,CPU被限制在10%。
- 9:42 nginx日志记录到的请求数量骤降,返回值也从全是200变为504和499[2]。这应该是宕机开始发生的时间。
- 10:10 收到UptimeRobot的报警邮件
- 13:30 我看到邮件后做了简单处理,开启了Cloudflare及其Under attack模式
- 14:00 CPU使用率降至10%以下,burst capacity开始恢复
- 14:49 收到UptimeRobot的报警解除邮件,downtime总共4小时38分钟
- 15:15 攻击结束
复盘
灾难不会凭空发生,而是关键事件的连锁效应。
Disasters don’t just happen. They’re a chain of critical events.
——国家地理频道「重返危机现场」
这句话来自我小时候很喜欢的电视节目「重返危机现场」。每一起事故背后其实都有很多环节可以阻止事件发生或者减小损失,但是出于某些原因每一个环节都没有按照预期工作。那么这个事件中的”chain of critical events”是什么?
- 网站受到攻击,攻击者发送了大量POST /xmlrpc.php请求
- 平时默认不开启Cloudflare,所有请求直接被服务器承受
- 由于阈值设置过高,自动化mitigation没有被触发
- Docker未能传递正确的IP,安全插件没有起作用
- 处理这些请求消耗了大量的计算资源,burst capacity耗尽,导致CPU被限制在10%。
- 由于配置有误,请求并没有直接由静态化缓存处理,而是仍然需要由php生成,导致在计算性能受限的情况下完全无法展示网页。
改进
禁用xmlrpc
WordPress依赖xmlrpc的主要功能仅有两个:Jetpack和Pingback。我选择从nginx层面禁止xmlrpc,仅向Jetpack的IP地址开放[3]。
始终开启Cloudflare
我之前没有开启Cloudflare反向代理的原因主要是Cloudflare会让来自中国的访客减速。经过测试后发现和直连相比,使用Cloudflare后从中国访问的TTFB从500ms增加到了900ms。虽然确实是比较严重的减速,但是还可以接受。以后视情况可能改为使用Cloudflare Tunnel。
调整报警/自动mitigation阈值
将自动升高Cloudflare的防护级别的触发值从50请求每秒降低到10请求每秒。
传递正确的IP
开启Cloudflare之后,大部分WordPress插件都可以自动从Cloudflare的header中读取真实IP地址,无需特别的配置。
正确配置静态化缓存
将Page Cache方式改为Disk Enhanced。
References
[1] Difference between w3total cache disk enhanced and disk basic – WordPress Development Stack Exchange

发表回复/Leave a Reply