新建一个scrapy项目
scrapy startproject spiderscrapy会初始化一个项目,项目文件包括:
items.py定制需要储存的文件的域,类似于ormpipelines.py管道settings.py设置相关参数spider文件夹 定制爬虫
scrapy爬虫的组成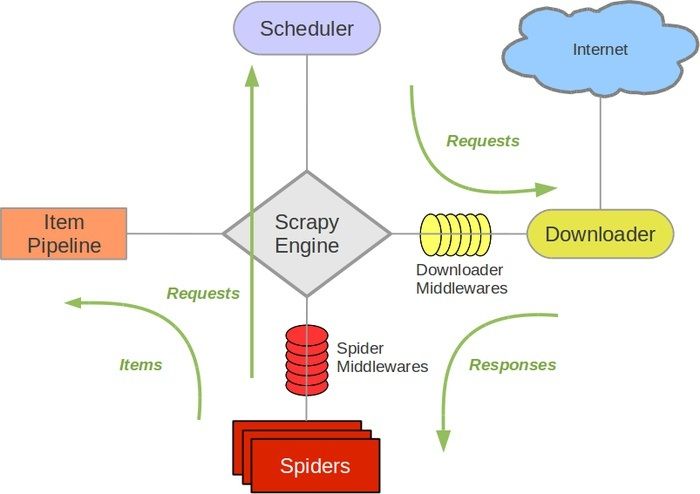
scarpy抓取一个页面的大致流程:
- 下载器下载HTTP响应内容
- 下载器传给执行回调函数进行解析
- 解析后调度器进行过滤,查重等等
- 将数据传给管道,作进一步处理
示例1
爬取www.xinli110.com上的文章标题
声明item
class XinliSpiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
content = scrapy.Field()抓取并处理第一个页面
在此之前,首先在settings.py中将pipeline相关语句取消注释
#coding:utf8
import sys
import scrapy
from scrapy.selector import Selector
from scrapy_demo.items import XinliSpiderItem
reload(sys)
sys.setdefaultencoding('utf-8')
class xinli_spider(scrapy.Spider):
name = "xinli"
allowed_domains = ["www.xinli110.com"]#允许抓取的域名
start_urls = ["http://www.xinli110.com"]#起始url
def parse(self, response):
#抓取网页后会默认调用parse函数进行处理
sel = Selector(response)
#使用xpath选取html元素
title = sel.xpath("//title").extract()
item = XinliSpiderItem()
#由于sel.xpath().extract()返回的是一个list,所以先使用for遍历
item['title'] = [n for n in title]#将title中的内容赋值给item
yield item#将item中的数据交由pipeline进一步处理
pipelines.py:
#coding:utf8
import sys
reload(sys)
sys.setdefaultencoding('utf8')
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
class ScrapyDemoPipeline(object):
def process_item(self, item, spider):
#从item中读取数据并打印
print item['title'][0]
执行后会抓取并打印所有抓取到的网页标题
递归抓取整个网站
#coding:utf8
import sys
import scrapy
from scrapy.selector import Selector
from scrapy.contrib.spiders import CrawlSpider, Rule
from scrapy.contrib.linkextractors.sgml import SgmlLinkExtractor
from scrapy_demo.items import XinliSpiderItem
reload(sys)
sys.setdefaultencoding('utf-8')
class xinli_spider(CrawlSpider):#CrawlSpider类继承自Spider类,可以通过定义rules属性实现递归抓取
name = "xinli"
allowed_domains = ["www.xinli110.com"]#允许抓取的域名
start_urls = ["http://www.xinli110.com"]#起始url
#定义rules属性
rules = (
Rule(SgmlLinkExtractor(allow=(r'\/qsnxl\/(xlq\/xljb|xljb|zd|fd)\/\w+\/\d+\/\d+.html')),#使用正则表达式匹配符合要求的网页
callback='parse_item',#回调函数
follow=True#是否跟进此页上的url,如果callback为空的话则默认为true
),
)
def parse_item(self, response):
#抓取网页后会默认调用parse函数进行处理
sel = Selector(response)
#使用xpath选取html元素
title = sel.xpath("//title").extract()
item = XinliSpiderItem()
#由于sel.xpath().extract()返回的是一个list,所以先使用for遍历
item['title'] = [n for n in title]#将title中的内容赋值给item
yield item#将item中的数据交由pipeline进一步处理
示例2
爬取icarus.silversky.moe:666上特定分类的图片

发表回复/Leave a Reply